
MetaLocator leverages globally distributed, load balanced Web and database servers to provide maximum speed, up-time and reliability. We contract with multiple providers to provide the highest level of redundancy and distributed architecture.
In our infrastructure planning, we emphasize distributed caching and cloud-based hardware redundancy.
We provision services from world-class providers including:
MetaLocator positions its infrastructure globally and has hosting capacity in Chicago, IL, USA (ORD), Ashton, VA USA, London, UK, and Oregon (Amazon US-West) and Amazon US-East. We choose multiple global providers and balance traffic according to an internal algorithm that considers geography, system load and customer.
MetaLocator is monitored 24x7 by a third party monitoring service with its own set of globally distributed monitoring servers. Our technicians are notified within 60 seconds of any service interruption.
We maintain an hierarchy of backups on-site and off-site with a 3rd-party provider. We also have hot-spare servers in the US midwest and Western US.
A simplified view of this redundant architecture is shown below:
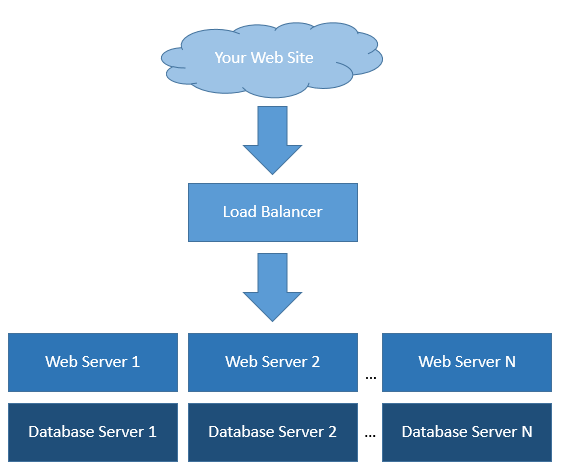
Facility qualifications vary depending the provider, but maintain the highest minimum quality standards including:
N+1 redundancy backup power
N+1 redundant cooling system
24/7 monitored fire suppression
24/7 armed security
This article describes our infrastructure in a general manner. For security purposes we do not publicly disclose many details of our infrastructure.
Disaster Recovery
MetaLocator is built around distributed computing, providing for a highly available architecture. We also plan for the worst and include the following Disaster Recovery Plan (DRP). Our plan considers a catastrophic failure at the data-center level. This type of incident would be caused only by significant Acts of God, war, terrorism, etc.
If you are more interested in what happens if you accidentally delete your data, we maintain off-site daily backups of each customer data set indefinitely which can be restored upon request.
We maintain an internal, detailed DRP which we do not publicly disclose for security purposes. The highlights of that plan include:
Acknowledgment: Due to the globally distributed nature of our monitoring system, MetaLocator staff would be notified immediately of any system availability issues. The DR Team will be activated within seconds of an incident.
Assessment: The DR Team will assess the extent of the damage and prepare a Recovery Plan. The Recovery Plan will leverage the distributed resources to create a path to re-deploy the MetaLocator infrastructure to a new Data Center.
Action: The DR Team will deploy the MetaLocator Application to a new Data Center and restore customer data from the most recent off-site backups.
Admission: The DR Team will report the successful restoration of MetaLocator's software and customer data to the Executive Team. The Executive Team will report publicly to MetaLocator's customer base regarding the status of the application, what happened, and how it may be avoided in the future.