
Importing data commonly starts with preparing your data in a spreadsheet format. To view a sample spreadsheet, right click this link and choose Save as. This file will open in Excel, Google Spreadsheets and OpenOffice. MetaLocator highly recommends that you work in the CSV UTF-8 file format. Other formats can introduce formatting and other non-data elements that can confuse the importer.
For tips on how to create a properly formatted import file, see this article.
A few important things to note about your CSV file:
There should be one row in your spreadsheet per record
The only required column is "Name", but the more information provided the better.
MetaLocator will create custom fields from columns it does not recognize.
For proper display of International characters and accented characters, such as "œ" your file must be UTF8 encoded.
When saving your file as a CSV, choose "Windows CSV"
Data Source
To begin importing your file, choose your Data Source. In this example, we will chose CSV.

In the next screen, pick the CSV file you have prepared from your computer.
Articles specific to other data sources can be found here:
Match Columns
Once the file is uploaded, MetaLocator will look at the data and attempt to match your columns to the MetaLocator System Columns.

If MetaLocator has encountered fields that do not match system field names or existing field names, it will display them as red columns as shown above. By default, unmatched fields will be created as custom fields.
Important: If you import your address data with field names that do not match the MetaLocator System field names, you must map your columns to the MetaLocator System columns. For example, MetaLocator's System field name for the location street address is Address. If you import address data in a column called Address 1, or Street Address you need to map this column to MetaLocator's System Address field by choosing Address from the drop-down box that contains the MetaLocator System field names underneath your provided column name. If you skip this step, MetaLocator will create a custom field that would not be properly recognized as the record's physical location. To be safe, use the field names as provided in the sample spreadsheet above.
Import Options
On this step you can choose any options for this import task.
Each option has a tooltip explaining it's purpose further which can be displayed by hovering your mouse over the label. They are as follows:
Add. With this option, MetaLocator will ignore the existing data and simply add the data being imported to the database. This option can create duplicates. This is the default operation.
Replace. In this scenario, MetaLocator will first delete all data in the destination table. It will then proceed with the import by adding the data being imported into the database, just as in the Add operation above. In this scenario, the resulting data set should mirror exactly the data source used to import.
Update Existing and Insert New. This option looks at each row in the incoming data and compares it to the data in MetaLocator. If a match is found, the record is deemed "Existing" and the record is updated according to the incoming data. If a match is not found, the record is inserted as new. See How MetaLocator Finds Matching Records below for more information on the matching process.
Skip Existing and Insert New. This option looks at each row in the incoming data and compares it to the data in MetaLocator. If a match is found, the record is deemed "Existing" and the record is ignored. If a match is not found, the record is inserted as new.
Update Existing and Skip New. This option looks at each row in the incoming data and compares it to the data in MetaLocator. If a match is found, the record is deemed "Existing" and the record is updated according to the incoming data. If a match is not found, the record is ignored.
Append. This uncommonly used option is for building long lists within a single field in MetaLocator, typically as part of a territory field. For example, if your import file includes two columns, an external key and a postal code, and the key is repeated for each postal code that comprises the territory for that location, and the postal code column is mapped to a column of type Territory Postal Code, the result will be a newline delimited list of all Postal Codes for the external key as shown below. During an append import, there is also an option to empty the territory column before importing, so the final value reflects the imported file, as opposed to adding to what exists in the field before the import. If you are using a composite external key, ensure your composite key is field has a lower Order than the territory field.

Leaving all options at the default settings will add the data you are importing to your existing data and no existing records will be affected.

Limiting Update Operations
When updating records, sometimes it is preferable to limit those updates to a specific set of records. This can be important when filtering the source data is not practical. In this scenario MetaLocator can be configured to limit update operations to rows where a specific field contains a specific value. In the example below, the import is configured to only update where the TLD field is set to US.

The columns listed in the "Update matched only where" dropdown can be customized to include additional fields configured as Admin filter fields.
Import Summary
After choosing Import options, click Next and your data will be imported according to your choices. Any errors will be displayed.
If MetaLocator encounters data with address information, but no latitude and longitude values, it will prompt that Geocoding is Needed. Click the button as indicated to geocode your data.
Any data quality issues will be summarized on this screen. The Data quality issues report reflects all data in MetaLocator, not only the data just imported.

Analytics Implications of Import Options
When data is inserted as new as in a Replace, Add or "Insert New" operation, it is assigned a non-repeating unique ID number by MetaLocator. This number is used in our Analytics system to track activity by record. If data is deleted or replaced, those keys are "orphaned" and the history of the record can be lost. Therefore, we recommend using a synchronization option such as "Update Existing and Insert New". Preferably with an External Key in place. External Keys avoid an issue where a location address has changed, and the address can no longer be used to uniquely identify a location.
Deleting Records During Import
When choosing Update Existing & Insert New, the system also displays an option to Delete records. For this feature to work, an external key must be present in your data. When this option is selected, MetaLocator will delete records from your MetaLocator account that it does not find in your imported spreadsheet based on a matching External Key. You can add an additional clause to this feature that limits the deletion to records that match the provided criteria. In the screenshot below, the system will import data by updating existing records, and inserting new records while deleting any locations not found in the import file that also have a TLD value of "US".

How MetaLocator Finds Matching Records
When updating existing records based on a match found between the existing MetaLocator database, and the spreadsheet being imported, there are 3 ways MetaLocator can determine a record match.
MetaLocator can determine a match by Address, which in this context is defined as the Address, City, State and Postal Code fields. Those fields combine to create a unique key with which MetaLocator can identify and compare an existing record to what is being imported.
If the MetaLocator ID is present (as labelled by the column "ID"), MetaLocator will use that value instead of the address.
Additionally, if an External Key field has been found, MetaLocator will use that as the unique value.
Based on a match, MetaLocator can Skip the record (and it will not be imported). Or it can Update the record's other fields. See the section above regarding Import Options for further detail.
Importing Categories
Categories can be imported alongside your data. Each row can include multiple categories by specifying additional columns called "Category1", "Category2" and so on as shown below:
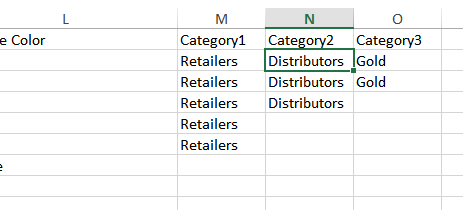
If the categories do not already exist in the system, MetaLocator will create them automatically during the import process.
Categories can also be imported in the following format, where "Retailers" is the category name. Y, Yes, 1 and TRUE are all supported values. In the example below the locations in rows 2,3,4 and 5 would be added to the "Retailers" category.

Group Names
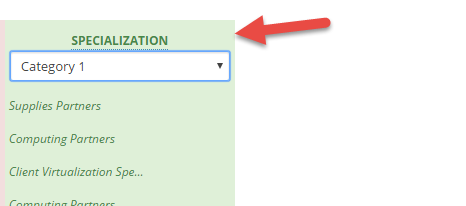
If a column in your spreadsheet is mapped to a Category column during the import "Match Columns" step, MetaLocator will automatically use the original column name as the Category Group Name when creating the category. In the below screenshot, the Category Group Name will be "Specialization". The group name setting only occurs when the category is created automatically during the import process. To set a group name after a category has been created, use the Bulk Actions menu under Categories.
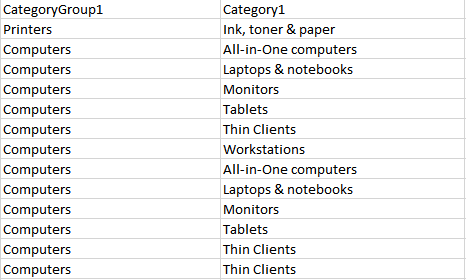
To create multiple group names in a single column you can specify the category group as "CategoryGroup1" for a corresponding "Category1" field as shown below
Collapsing Duplicate Rows
If your data is repeated by location, MetaLocator can combine those duplicates if the "Update Existing and Insert New" option is checked. This is particularly useful if you have some columns that don't duplicate by row, such as a category as shown below:

When importing this data set, if the SPECIALIZATION column is mapped to a Category column during the import process as shown above, the system will insert a single location and automatically include it in all four categories listed. The system recognizes that these are the same locations using the uniqueness process described above.
Import Validation
MetaLocator imports data "as-is", attempting to assimilate as much data from the imported file as possible. However, validation expressions can be provided under Data > Fields as shown below. These validation expressions can enforce format requirements and required fields during bulk imports.

Field validation will accept a PCRE-format regular expression. If the expression matches the value provided in the field, it will be accepted. If it does not, the field value will be emptied before the record is saved. This is good for rejecting invalid field values during import, but still accepting the rest of the row.
Row validation will also accept a PCRE-format regular expression. If the expression matches the value provided in the field, it will be accepted. If it does not, the entire row will be rejected. This is good for establishing required fields or other criteria that should cause the system to reject an entire row.
To reject a row that is empty follow the logic below:
